Abstract
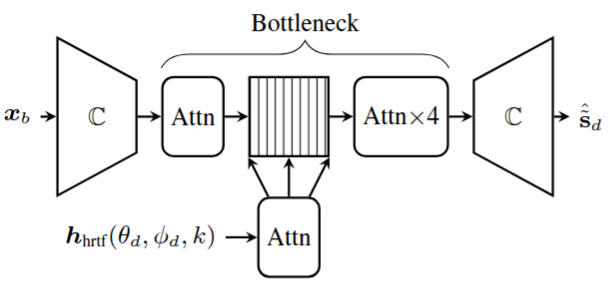
In this work, we aim to imitate the human ability to selectively attend to a single speaker, even in the presence of multiple simultaneous talkers. To achieve this, we propose a novel approach for binaural target speaker extraction that leverages the listener’s HRTF to isolate the desired speaker. Notably, our method does not rely on speaker embeddings, making it speaker-independent and enabling strong generalization across multiple speech datasets in different languages.
We employ a fully complex-valued neural network that operates directly on the complex-valued STFT of the mixed audio signals, and compare it to a RI-based neural network, demonstrating the advantages of the former.
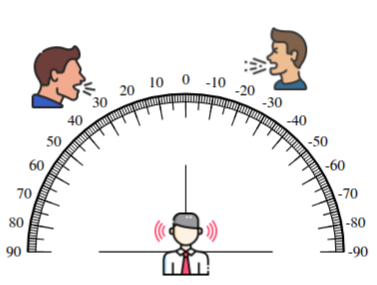
We first evaluate the method in an anechoic, noise-free scenario, where it achieves excellent extraction performance while faithfully preserving the binaural cues of the target signal. We then extend the evaluation to reverberant conditions. Our method proves robust, maintaining speech clarity and source directionality while simultaneously reducing reverberation.
A comparative analysis with existing binaural TSE methods demonstrates that our approach attains performance on par with competing techniques in terms of noise reduction and perceptual quality, while offering a clear advantage in preserving binaural cues.
_elev_tensor([0]).png)
_elev_tensor([-10]).png)
_elev_tensor([0]).png)
_elev_tensor([0]).png)
_elev_tensor([0]).png)
_elev_tensor([10]).png)
_elev_tensor([0]).png)
_elev_tensor([-10]).png)